
引き続きMethodsの読み方について考えていきます。
ここでは「臨床的疑問に対する直接的な研究か」「複数名のレビュアーで文献が選択されているか」の2点について考えていきます。
前回までの記事はこちら
実臨床に役立てるメタアナリシスの読み方① システマティックレビューとメタアナリシスの違い『なぜメタアナリシスのみはダメなのか』
実臨床に役立てるメタアナリシスの読み方② -Background編〜Methods編前半
まとめたページと参考文献はこちら
目次:
臨床的疑問に対する直接的な研究か
これは「臨床への適用」を考える上で特に重要になってくる話です。
まず読み手としては持っている臨床的疑問に対して、メタアナリシスの結果として効果がどの程度かを確認していくわけです。しかしながら、メタアナリシスの効果を直接患者さんに適用しようと思っても、患者さんの状態や治療薬の内容や量、アウトカムの内容が違ってしまっては、予測される効果はメタアナリシスの結果からずれてしまいます。
では何がどうずれることが問題なのでしょうか。
これも前回同様にinclusion/exclusion criteria, intervention, control, outcomeを見ながら考えていきます。
より具体的には
・対象による薬の効果の違い
・プラセボ対象/実薬対象の違い
・エンドポイントの違い
の3点に着目します。
この辺の話はランダム化比較試験の読み方にも共通することなので、論文の読み方関係の本でもよくみるかもしれません。
集めようとした文献の基準はMethods, 実際に集まった文献はResultsに書かれていますので、今回の項目は両方を眺めながら検討していきます。
対象による薬の効果の違い
inclusion/exclusion criteriaを読むと大体の患者層が分かりますが、それが実際の患者さんと一致するかどうかが重要です。高齢者であれば薬剤の代謝が異なって同じ量でも強く効いてしまう可能性があります。また、病気の重症度や時期が異なれば、効き目がまるで違う場合もあります。
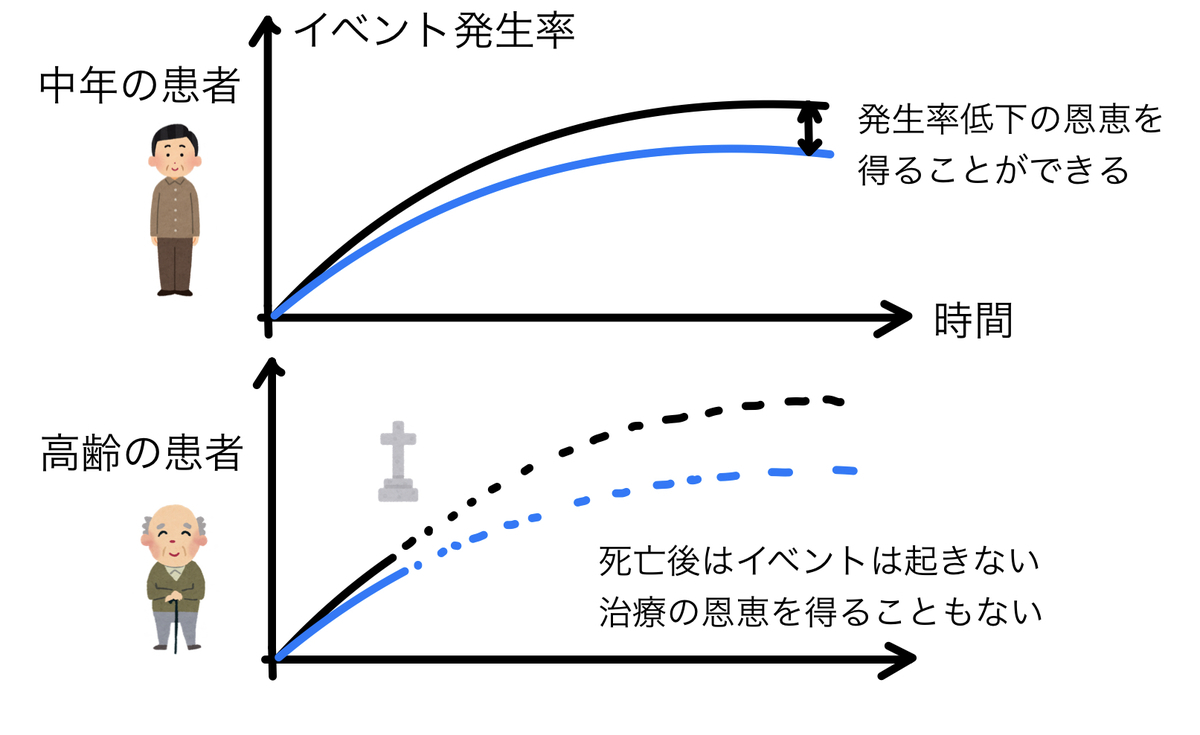
他にも高齢者の多い日本において、問題となるのは競合リスク(competing risk)の問題です。競合リスクの問題とは複数の種類のイベントがある場合、最初に起きたイベントしか観察できないという問題を指します。
例えば、脳梗塞と死亡、という複数のイベントがあったとき、当たり前ですが死んでしまったら脳梗塞は起きません。
つまり110歳の方を対象にアスピリンを内服させて、その後10年間に脳梗塞の再発があるかどうか調べた試験があった場合、10年間の脳梗塞再発を100%防げるなんて可能性もあるわけです。なぜなら寿命を考えると、脳梗塞再発よりも前に亡くなる確率が高いため、脳梗塞再発が確認できる確率はかなり減るからです。これが競合リスクの問題です。
患者さんに適用する場合にもこの問題は起きます。例えば50歳代の患者さんに抗凝固薬を飲ませて「2年間の脳梗塞の再発率が6割減りました」という試験があったときに、90歳代の患者さんに同じ薬を飲ませて、同様の効果は得られるでしょうか。おそらくそれは無理でしょう。実際に適用するうえではこのように他に起きうるイベントについても考慮しなければいけません。

図:競合リスクの問題
また少し直接的な薬の効果からは離れますが、一般的に臨床試験に組み込まれる患者さんは、①理解度がよい、②コンプライアンスが良い、③合併症が少ない、④大規模な治療施設に通院している、などの傾向があります。実際の患者集団よりもアウトカムの数値が良くなる可能性があるわけです。
さらにホーソン効果といって、試験として結果を期待されていると思うと、結果を良くしようと頑張ってしまう可能性もあります(こうした効果が本当にあるかどうかはまだ議論の的だと思いますが)。総じてアウトカムが良くなりやすいことを考慮しておかないといけません。
プラセボ対照か実薬対照かの違い
この項目はintervention/controlの部分をみて検討していきます。
メタアナリシスに含まれる試験はプラセボ対照の試験を集めることが多いと思います。実薬対照だと統合する際の効果の比(あるいは差)がプラセボとは異なったものになってしまうためです。通常は、実薬との差の方がプラセボよりは小さいものになるでしょう。
ただ、実際の場面で患者さんは別の薬Aを飲んでいて、新しく別の薬Bに切り替えたい、という場合が想定されます。その場合は本来AとBを比較した研究がたくさんあればメタアナリシスで統合した結果を参考にできるのですが、実薬対照の研究は基本的にそんなにたくさんありません。二つを比較して優劣がついた場合、何度も同様の研究を行うのは倫理的に問題が生じるからです。
では、薬Aとプラセボを比較した試験のメタアナリシスと薬Bとプラセボを比較した試験のメタアナリシスの結果を見比べればよいのかというと、それはダメです。
大抵の場合、対象となる患者層が異なっているため直接的に数値を比べることはできないからです。
ネットワークメタアナリシスという方法論ではこれらをそれぞれ比べることも為されますが、エビデンスの強さという面ではやや信頼性に劣ります。
以上のことから薬の切り替えを想定する場面では臨床的に適切な回答は得られにくいと考えられます。
エンドポイントによる違い
この項目はoutcomeの欄を確認していきます。そこでみるべきポイントは“代用エンドポイント”かどうか、“エンドポイントはハードなのかソフトなのか”という点です。順番に説明していきます。
まず試験の結果として示されているエンドポイントが本当に意味のあるエンドポイントではない場合、期待された効果が得られる保証がない点に注意しないといけません。
例えば、60代の糖尿病の患者さんへの経口糖尿病薬で心血管イベントの抑制をしたいと思ったとしましょう。
その時、調べた経口糖尿病薬の試験のエンドポイントは「HbA1cを下げる」だったとします。
果たしてこの試験の結果をみて、心血管イベントの抑制は期待できるでしょうか。
必ずしも期待はできません。「HbA1cを下げれば糖尿病が良くなっているわけだから、心血管イベントは絶対に減る」という発想は正しくないと言われています。
例えば有名な例としてDPP4阻害薬のSitagliptinでの心血管イベント抑制をみたランダム化比較試験をみると分かります。
Effect of Sitagliptin on Cardiovascular Outcomes in Type 2 Diabetes
HbA1cは低下していますが、心血管イベントは減っていません。
この問題は結構難しいもので、例えば血圧についても同様な指摘が考えられます。血圧の数値を下げる作用が強いからといって必ずしも心血管・脳血管イベントの抑制や腎機能悪化に良いわけではないわけですね。
ここで出てきた「血圧」や「HbA1c」などの望まれる直接的なエンドポイントの代わりとして使われるものを”代用エンドポイント(surrogate endpoint)”といいます。
代用エンドポイントと望ましいエンドポイント同士の密接な因果関係が示されていればよいのですが、実際それを示すのは難しい場合が多いです。
最近の脳神経内科界隈では話題のアルツハイマー型認知症に対する薬”アデュカヌマブ”が承認された1番の理由はまさにその代用エンドポイントによるものです。
認知機能スケールの低下を抑制するという望ましいエンドポイントでは、過去の2つの研究データを組み合わせる(しかも中間解析で中止になっている)という荒業で有意差を出したに過ぎませんでした。その差も小さいものに留まっています。
ですが、FDAが承認した主な理由はアミロイドPETによってみられるアミロイドプラークの減少で治療効果が期待できるから、というものです。これで迅速承認(accelrated approval)しています。まさにこれこそ”代用エンドポイント”です。本来のエンドポイントのほうが重要視されるべきであることは言うまでもありません。
これまで同様の機序の薬が数々失敗してきたことを考えると、この代用エンドポイントが望ましいエンドポイントと密接な関係があるかと問われると、、、悩まざるを得ないところがあります。
この辺の話題は友人のブログが十二分にまとめてますので、興味があればこちらをどうぞ。
期待の新薬?アデュカヌマブが抱える現実的問題 12 選-エビカツ横丁
このように代用エンドポイントは必ずしも本当に患者さんのためになるものではない可能性があります。メタアナリシスで統合された結果が代用エンドポイントである場合、その目の前の患者さんに大した意味を持たない可能性もあることを踏まえて考えないといけません。重要なエンドポイントで効果が証明されている薬と代用エンドポイントでしか効果が証明されていない薬が選択肢にあるのであれば、前者をぜひ検討したいところです。
また、同様に問題となるのはエンドポイントがソフトかハードかという問題です。
ソフトエンドポイントというのは評価者によって変わりやすい性質のあるエンドポイントを指します。例えば「脳梗塞における麻痺の悪化」なんていうのは中々困ったエンドポイントです。NIHSSなどのスコアリングで示すなら良いですが、麻痺が悪化したかどうかというのは微妙な差である場合、評価者によって意見が変わる可能性があります。
「心不全入院」も心血管関連の研究でよくみるアウトカムですが、入院の基準が明確でない場合は、人によって判断が変わってしまうため、ソフトな面も生じてしまいます。
逆にハードエンドポイントは、人によって評価が変わりえないものを指します。究極的なものは「死亡」です。追跡できている限り「死亡」は人によって評価が絶対に変わらないものなので、強いハードエンドポイントとなります。
統合された結果がソフトエンドポイントに近ければ近いほど、患者さんにおいて同様の効果が得られるかどうかは不確実なものになっていきます。
複数名のレビュアーで文献が選択されているか
続いては、methodsに必ず書いてあるレビュアーの人数と文献の選び方についてです。
前回記事で述べたように、システマティックレビューでは文献を選別する基準が設けられています。ただ、その基準に当てはまるかどうか微妙なラインの研究が存在することが実際あります。そうした時に、一人のレビュアーが線引きをしてしまうとどうなるでしょうか。
そのレビュアーが自分が研究して推奨している仮説を支持するような論文を選んでしまうかもしれませんし、COI(利益相反)のある企業の薬を推奨するような論文を選んでしまうかもしれません。こうした偏りのことを評価者バイアスと呼びます。
メタアナリシスはどうしても事後的な解析になるため、バイアスを避けることが何よりも重要になってきます。そこで、迷った時は複数のレビュアーで文献を選別するような仕組みがあればより安心できると言えます。
論文によっては2人で吟味し、さらに意見が異なった場合は別の1人と相談する、という方法をとっているものもあります。複数人で評価されているということは最低限保障されないといけないと思われます。
まとめ
・臨床との患者層と薬剤の違いには要注意
・代用エンドポイント/ソフトエンドポイントかどうかを確認すべし
・評価者バイアスを意識しよう
次回の記事ではメタアナリシスにおける最大最強のバイアスである「報告バイアス(reporting bias)」を中心に書いていきます。
次回の記事はこちら
実臨床に役立てるメタアナリシスの読み方④ -Methods編中盤②- – 脳内ライブラリアン











コメントを残す