
いざ文章を英語で書こうと思ったときに、適切な表現が分からず、書き方に困ることはよくあることかと思います。
自分の場合は論文を書くときにそういったことで良く困ってます。間違えると、内容以外の点でrejectの一因になってくるので切実です。
そこで、やられるのは他の論文や文章から役に立ちそうな表現を集めてきて、剽窃にならないように改変しつつ使うといったことでしょうか。
ここで困るのは単語同士の組み合わせです。他から表現を持ってきたは良いけれど、どれとどれなら組み合わせて使って良いのかが困る点であり、間違えることがあるところです。
「この組み合わせはおかしい!」と分かるようなネイティブの感覚は持ってないですし、Google検索で同様の表現があるか検索はできますが結構間違ってることも多いです。
そこで、今回は英語表現が正しいのかどうか、どんな組み合わせならば自然なのか、コーパス言語学を使ってそういったことが学習できる方法、より具体的にはコーパスの一つであるCoCAの使い方を紹介してみます。
目次:
そもそもコーパス(corpus)とは
「コーパス」は言語学分野の専門用語で書き言葉や話し言葉を集めたデータベースのことを意味します。膨大な量の文章や話し言葉を集めることで、出てくる言葉の頻度・関係性などを分析し、言語の特徴の解明や、自然言語処理、書き手の特定、時代による言語の変化の研究等を行うことができます。
これが英語学習に何の役に立つのでしょうか。
例えば、日本語を知らない外国人が「ブログ」という言葉を使ってみたい、とします。「ブログを書く」「ブログをアップする」とは言いますが、「ブログを描く」「ブログをアップロードする」という表現は何となく使わないと思います。意味を解釈しようと思えばできますがどことなく不自然な表現です。
そこで、コーパスを用いて文章の頻度を検索すれば、明らかに後者の言葉の出現頻度は低いので、自然な表現ではないということが分かります。こういった頻度の比較はgoogle検索では十分にできません。また、「書く」「アップする」という表現を知らなくても、「ブログ」と関連しやすい動詞をコーパスで調べれば、そうした表現に気づくこともできます。これを英語で利用しよう、というのが今回の記事の目論見です。
世界初の英語コーパスは1964年に完成されたBrown Corpusとされており、100万語ほどでしたが、現在はインターネットとPCの普及もあり、データベースの構築がより容易となったため億単位規模のコーパスが多数存在しています。しかも、無料で使えます。*1
ちなみに、億単位の単語量のあるコーパスを構築するには言葉のどこまでをどのように収集するですが、多くの場合は”均衡的収集法”という方法が使われます。*1この方法では、まず大まかにジャンル毎で言葉の種類を層別化します。例えば、小説、新聞、雑誌、話し言葉、学術論文etc…。こうして作った層が大体言葉全体の何割を占めるか割り振ります。これを仮想の母集団として、統計学のごとく同じ割合になるように、各ジャンルから無作為に標本抽出をします。こうしてコーパスを作る方法が均衡的収集法と言われます。
続いて、造られたコーパスからどうやって英語表現を磨いていくかをコーパスの一つであるCoCAを例にとって具体的な方法を紹介していきます。
コーパスにおける用語説明
実際のコーパスを使っていくうえで知っておきたい用語を説明します。
コンコーダンス(concordance)
いわゆる用例と同じような意味です。コンコーダンス検索ということをすると、調べたい単語の入った例文がざっと並びます。調べたい単語が真ん中に並び、周辺に前後の文章が並ぶKWIC(keyword in context)形式と呼ばれる形で結果が出されることが多いです。
オンライン辞書でも例文はみられると思いますが、コーパスでは表示される量がはるかに多いのと、前後の文脈もより広くみられることが特徴です。端的な例文では正直使い方が分かりにくいことが多いので、そういった点ではコーパスに利点があります。
共起表現(collocates)
どの単語と単語が関連性が強いか(=一緒に用いられる頻度が多いか)を示すのがcollocatesです。ある語と一緒に用いられやすい言葉が分かります。文章中で隣接していなくても、3-4語離れていても検出したり、設定は色々です。
例えばreveal(~明らかにする)と言う単語だと、名詞ではstudy, analysis, difference,…などの単語が並びます。共起表現から、学術的に用いられやすい単語であることが分かりますね。
単語連鎖(clusters)
clustersは隣接して用いられる単語の塊を検出します。句動詞(different from~とか)は多くがこれで見つかってくると思います。
CoCAの紹介と使い方
Corpus of Contemporary American English (CoCA)とは?
Corpus of Contemporary American English (CoCA)
2008年に構築されたアメリカ英語のコーパスです。語数は10億語に達しています(2020年現在)。上述した均衡的収集法を用いており、内容は話し言葉、小説、雑誌、学術論文、新聞、ウェブ、テレビ、ブログに分けられています。1年に2000万語追加され、年に2回更新され続けています。
例文もジャンルを表記してくれるので学術論文の表現を探したい自分にとっては役に立ちます。ちなみにサイトからiWeb(140億語以上を収集したとんでもないWEB表現のコーパス)などの他の代表的なコーパスに飛ぶことができるので同じような使い方で他のコーパスも使うことができます。
CoCAの簡単な使い方
CoCAは結構情報量が多いので、簡単な見方だけ紹介していきます。
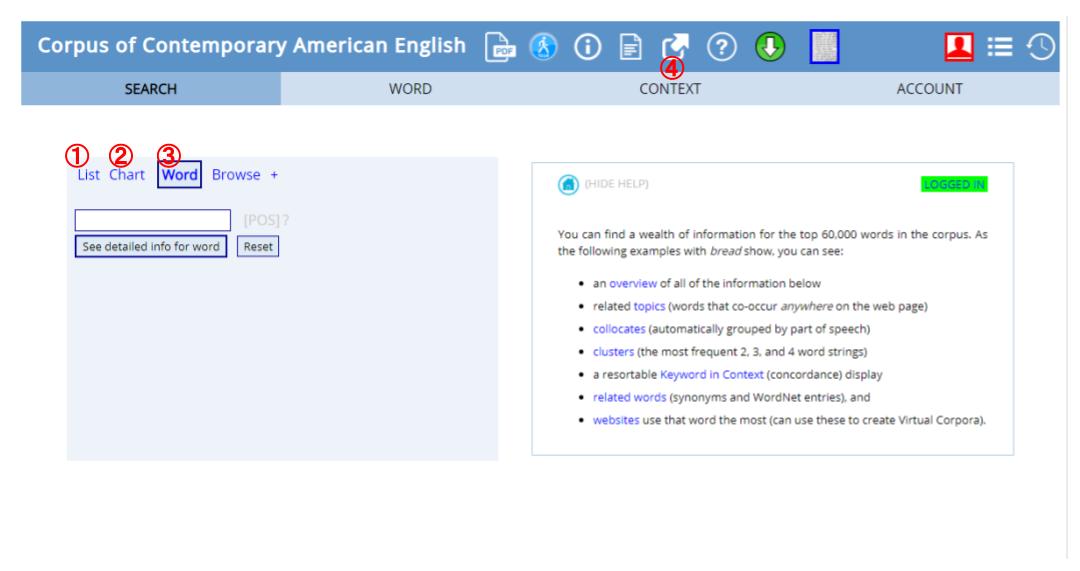
まず上記リンクから飛ぶとこのような画面になります。

(https://www.english-corpora.org/coca/より引用)
検索を行うためには無料の利用者登録が必須となったようなので、指示に従ってアカウント作成し、ログインできるようにします。
まず①~③の部分を押して、そのあと下の空欄にいれると単語の検索ができます。
①はコンコーダンス検索です。文章中での使われ方がリストになってざっと並びます。スペースで区切って複数語も検索可能です。
②はジャンルと年代ごとの頻度が分かります。どのような場面で使われるのか、またいつ頃よく使われている言葉なのかがよくわかります。
③は単語検索で、一語のみでの検索となります。画面が切り替わって共起表現や単語連鎖の検索ができます。(下図に続きます)
単語が名詞、動詞など複数の品詞をとりうる場合は検索フォームの横にあるPOS(Part-of-Speech)をクリックします。すると、品詞の選択ができますので、指定して選ぶことができます。
④はiWEBなどの別のコーパスに切り替えができます。
続いて、③の単語検索画面を見てみます。

(同HPより引用)
①は検索した単語です。先ほど例で出した”reveal”を入れてます。
②はジャンル毎の頻度がグラフ化されています。ACADは学術論文ですが、それが多いですね。
③TOPICSは単語があるところと同じウェブページ内に出てくる単語(同じ文章とは限らない)で頻度が多いものを挙げています。
④は上で説明した共起表現です。
⑤のリンクをクリックすると、共起表現や単語連鎖を見ることができます。
単語連鎖(クラスター)の検索画面はこんな感じです。

(同HPより引用)
青が濃いものであるほど頻度が高いです。一緒に使われる単語がパッと見て良く分かります。
単語同士の相性が統計的に整理された頻度をみてしっかりと確認できるので、論文を書く時の正しい表現を見つけるのにはうってつけです。例文に目を通すだけでも感覚が磨かれる感じもあるので、ぜひ英語で文章を書かないといけないような方は見てみることをお勧めします。
参考文献:
*石川慎一郎著『ベーシックコーパス言語学』










私は以前、自分の研究論文を翻訳会社さんに丸投げしてお願いしたことがあります。。。
今は機械翻訳もありますが、やはり専門性の関わる分野なのでお金を出してよかったと思っています。
ユレイタスという会社さんに頼みました。お勧めです^^(https://ulatus.jp/)
ちょっと面倒な作業をミニマムにして効率よく、時間を節約して、充実した院生活を送るかに重きを置いていました。
今後コーパスを活用できたらと思います。
大変有用な情報ありがとうございます。
>凪さん
コメントありがとうございます。自分で書けるのが一番でしょうが、修正してもらいながら、そこから学ばないと、独りでいきなりやるのは確かに難しいかなと思います。