
コロナ感染者も増えており、4連休も結局どこも行けないですね。。。まあ、仕事もあってそもそもそんなに行けないんですが。
引き続きRCTの勉強を続けます。
前回記事はこちら
ここまでは知っておきたいランダム化比較試験の読み方① – 脳内ライブラリアン
ここまでは知っておきたいランダム化比較試験の読み方② – 脳内ライブラリアン
今回は試験終了後の解析で生じる問題について書きます。

目次:
試験終了後の解析における障害について
試験終了時の細かいアウトカムの解析方法を全部挙げることは難しいので、「ランダム化比較試験」について注意すべき点は何か、に絞って説明します。
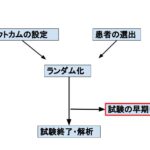
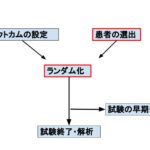
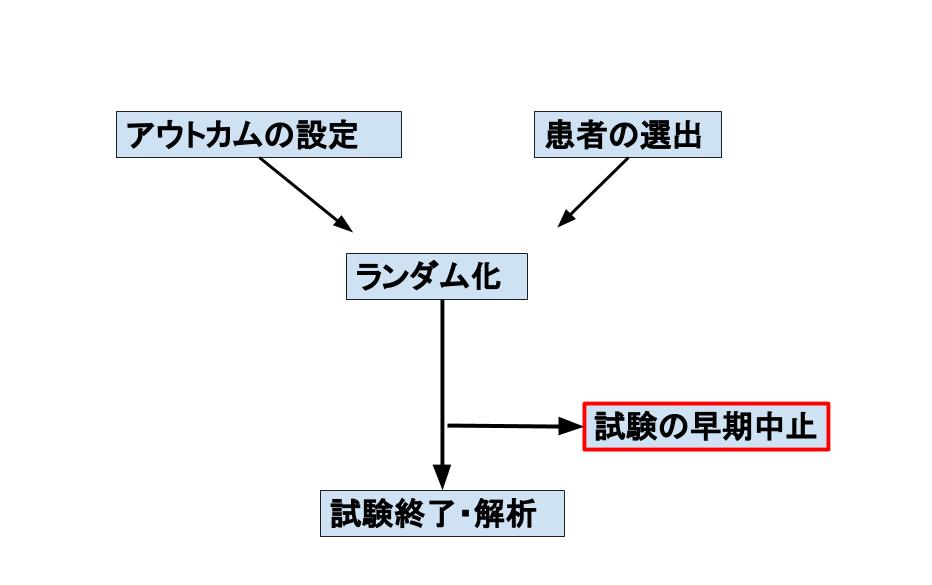
前回でも述べたようにランダム化比較試験においての肝は、そのままですが、「患者が2群にランダム化されていること」です。偏りがないことが介入の効果を示すうえで最も基盤となるからです。
そこでその障害となるのは何かといえば、「追跡不能例(lost to follow-up)」と「途中で治療が変わった例」です。
追跡不能例(lost to follow-up)
患者さんがフォローの外来に来なかったり、急に連絡がつかなくなったり、試験への参加継続を拒否されたり、いろいろな理由で追跡不能となることがあります。これが、lost to follow-upとして報告される例です。
減った分はアウトカムがどうだったのか当然分からないため、実はlostした症例にアウトカムが発生していた場合、試験結果に重大な影響を及ぼす可能性もあります。
単純にその影響を考えてみる場合には、追跡不能例の数をみて、その症例が介入群で全てアウトカムを起こし、逆にコントロール群ではアウトカムを起こさなかったとき、最終的な数値(オッズ比とかリスク比とか)がどうなるか計算してみると分かりやすいです。それでも数値に大きな変化が起きないようであれば、最悪の場合でもその試験の結果は揺らがないことになります。
Intention-To-Treat(ITT)解析
もうひとつの障害である「途中で介入群→コントロール群もしくはコントロール群→介入群」に治療が変わった場合どうするか、という問題への対策がITT解析です。
途中で治療が変わったときにそのまま実際にした治療で被験者をカウントする方法はper-protocol解析と言われますが、この方法の問題は最初に述べた一番大事な「ランダム化」が破綻してしまう可能性がある点です。初めにせっかくランダム化しているのに、あとから群の移動があると当然ランダム化が崩れます。仮に各群から移動する数が一緒だったとしても、背景因子に偏りが出る可能性があるので(例えば治療を変える人はみな高齢で薬の副作用が出やすかった、とか)そろえた背景が変わる危険性があります。
これに対してITT解析では実際の治療の方法が変わったとしても、同じ群としてカウントして解析を行います。「介入群→コントロール群」に変わった場合、介入治療を実際は受けていないので、当然ながら仮に効果がある治療だったとしても、その効果は出ないことになります。その分、実際の治療の真の効果よりも結果が下回って見えてしまう点は考慮が必要です。
ちなみにこのITT解析は上述の追跡不能例の問題については有効に作用しません。つまり、ITT解析していようがいまいが、追跡不能例が多ければ結果に影響を及ぼすのは変わりません。参考文献にある『JAMA User’s guide』に指摘されていましたが、論文によってはITT解析で追跡不能例の問題が解決するかのように書かれているものもあるようで、混同しないように注意が必要です。
また、このITT解析の問題は有害事象についても同様に考えることができます。per-protocol解析を行えば、有害事象は受けた治療に伴って出てくるのでそれぞれの群をお単独で見れば真の値に近くなりますが、ランダム化という点で2群を比較するときにはバイアスがかかります。
それに対してITT解析では実際に治療を受けていないとしてもそのまま割り付けてみるので当然有害事象は出にくいようにみえてしまいます。つまり、実際の有害事象の数値を下回ってみえてしまうのです。これをどっちの解析で行うかは悩ましいところですが、ITT解析で書かれているものは少なくとも実際よりは低めなんだという認識をもつ必要があります。
サブグループ解析の解釈
少し話が変わりますが、最後にサブグループ解析についてです。
サブグループ解析とは試験のアウトカムに対して、年齢、人種、性別、合併症の有無などなどそれぞれのグループごとにデータを解析したときに結果が異なるのかどうかをみる解析です。
これをどう解釈するかですが、基本的には「試験のアウトカムがどのグループでみても、そんなに大きく変わらないよね」ということを確認するために使います。「この年齢層だと効果が高いから、自分の患者さんもその年齢だし、どんどん使うべき」という解釈をしてはいけません。
なぜなら、サブグループにする時点で被験者数が減るため、検出力の問題も考えると統計的な有効性が明らかに下がるからです。本来の試験デザインから減った人数で解釈することには危険性が伴います。あくまで参考値と思う程度が良いと思われます。
次回は早期に中止された試験について書きます。
(2021.06.28追記 医学論文の読み方関係の記事はこちらにまとめました)
参考文献:
週刊医学界新聞のこちらの連載は結構勉強になりました↓
医学書院/週刊医学界新聞(第2825号 2009年04月06日)
未読ですが本も出されているようです。
前回同様に主にはこれを参考にしています。お勧めです。
邦訳版はこちら








コメントを残す