
今回で最後です。
研究毎の異質性の評価について書きます。
前回までの記事はこちら
ここまでは知っておきたいメタアナリシスの読み方① -システマティックレビューとメタアナリシスの違い- – 脳内ライブラリアン
ここまでは知っておきたいメタアナリシスの読み方② -バイアスリスクについて(risk of bias)- – 脳内ライブラリアン
ここまでは知っておきたいメタアナリシスの読み方③ -effect size, standard mean differenceについて/固定効果モデルとランダム効果モデル- – 脳内ライブラリアン
ここまでは知っておきたいメタアナリシスの読み方④ -フォレストプロット- – 脳内ライブラリアン
(2020.10.04追記)
より詳細なメタアナリシスの記事を追加しました
メタアナリシスについてより詳しく学ぶ①-fixed effects model, random effects modelと異質性
研究の異質性の評価

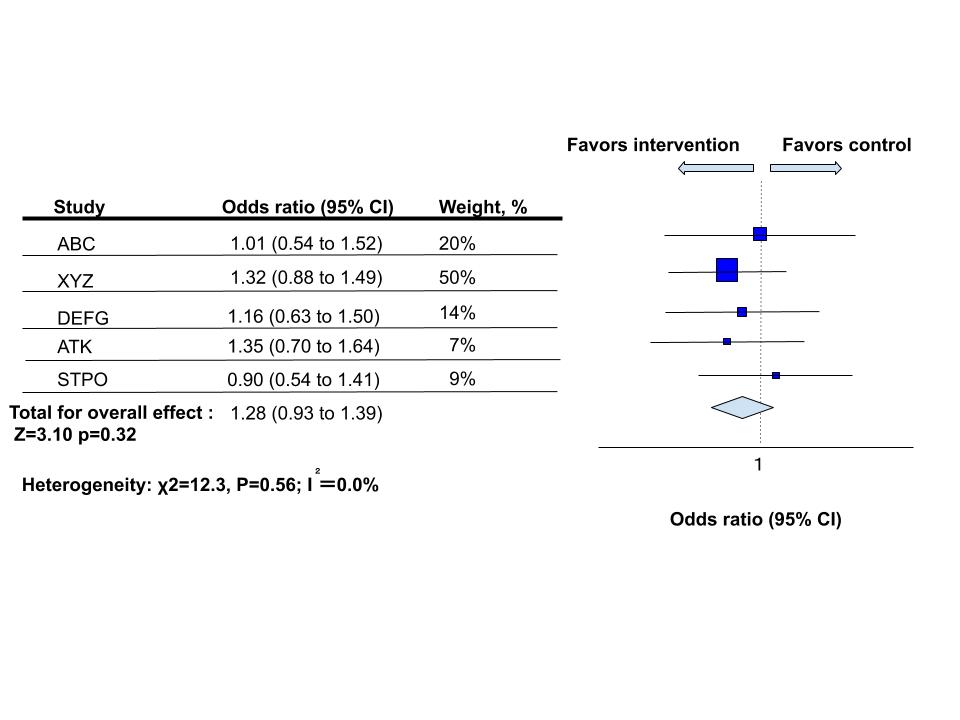
前回使った表で下の部分に”Heterogeneity”というのがあると思いますが、これは果たして何でしょうか。
メタアナリシスでは様々なタイプの研究を評価します。そこで、それぞれの研究が均質なのかどうかが重要です。逆に均質でない(=異質性が大きい)と問題です。あまりに違うものを集めてしまうと意味がないからです。方法としてCochran’s Q test(コクランのQ検定)や検定などが知られています。
Cochran’s Q test
χ二乗分布を使って、「帰無仮説:すべての研究のばらつきはたまたまである」を検定します。実際集めた研究の結果が一貫しているとしたら、「ばらつきはたまたま」であるはずなので、有意差は出ないことが望ましいといえます。よってp値は大きければよいです。上記の表ではp値が0.56と大きくなっているので問題なさそうです。
ただし、研究のサンプルサイズが小さいと研究の異質性を検出できない場合があるためサンプルサイズが小さいものでは過信できないと言えます。
 統計量
統計量
こちらも同様に均質性の評価する指標ですが、数値で程度を示すことが出来ます。

(JAMA Users’ Guide to the Medical Literatureより引用)
0%に近ければ研究が均質であり、100%に近ければ研究の異質性が大きいといえます。100%に至っては図において”Why are you pooling?”とまで書かれています(笑)
一般に目安としては50%未満が望ましいとされています。今回のメタ解析の表では0%となっており均質性が保たれていることを示しています。
まとめ
meta-analysisの結果の解釈と見方について今まで説明してきました。バイアスリスクと結果の統合方法や、フォレストプロットの形、研究の異質性、それぞれの評価が必要です。これによって信用性やインパクトがどの程度であるかを推し量ることができます。
また触れるところがなかったですが、個々の患者さんに結果を応用する場合、もともとのprimary outcomeとされるイベントのコントロール群での発症率と介入群でのRRR(relative risk reduction: 相対リスク減少率)が必要です。
逆に、大勢に治療を行った場合の変化についてはこれだと分かりにくいので、ARR(absolute risk reduction: 絶対リスク減少率)や逆数をとったNNT(number needed to treat)が分かりやすいと言えます。
細かい統計的な計算方法については述べていませんがまたどこかでやろうかと思います。
(2021.06.28追記 医学論文の読み方関係の記事はこちらにまとめました)
参考文献:











コメントを残す