

YouTube更新しました。
前回の動画でわずかに触れた「多重検定」の話をちょっとだけ掘り下げました。
予告の内容とは異なってます(汗
仮説検定において
・無計画に後付けで検定を繰り返す
・仮説検定をしまくって、P値が低い結果が出たものだけを発表する
といった行為はデータドレッジング(あるいはP値ハッキング)とも呼ばれ、本当はデータ間の違いに意味がないのに、さも意味があるかのようにみえてしまう問題があります。
なお、ドレッジング(dredging)は「川や湖の底にある土砂をさらう」ことを指しており、データを綺麗にしちゃうということですね。
もう少し詳しく知りたい方は新谷歩先生の『今日から使える医療統計』が参考になります。こちらでは複数回仮説検定を行うような例として以下の場合を挙げています。
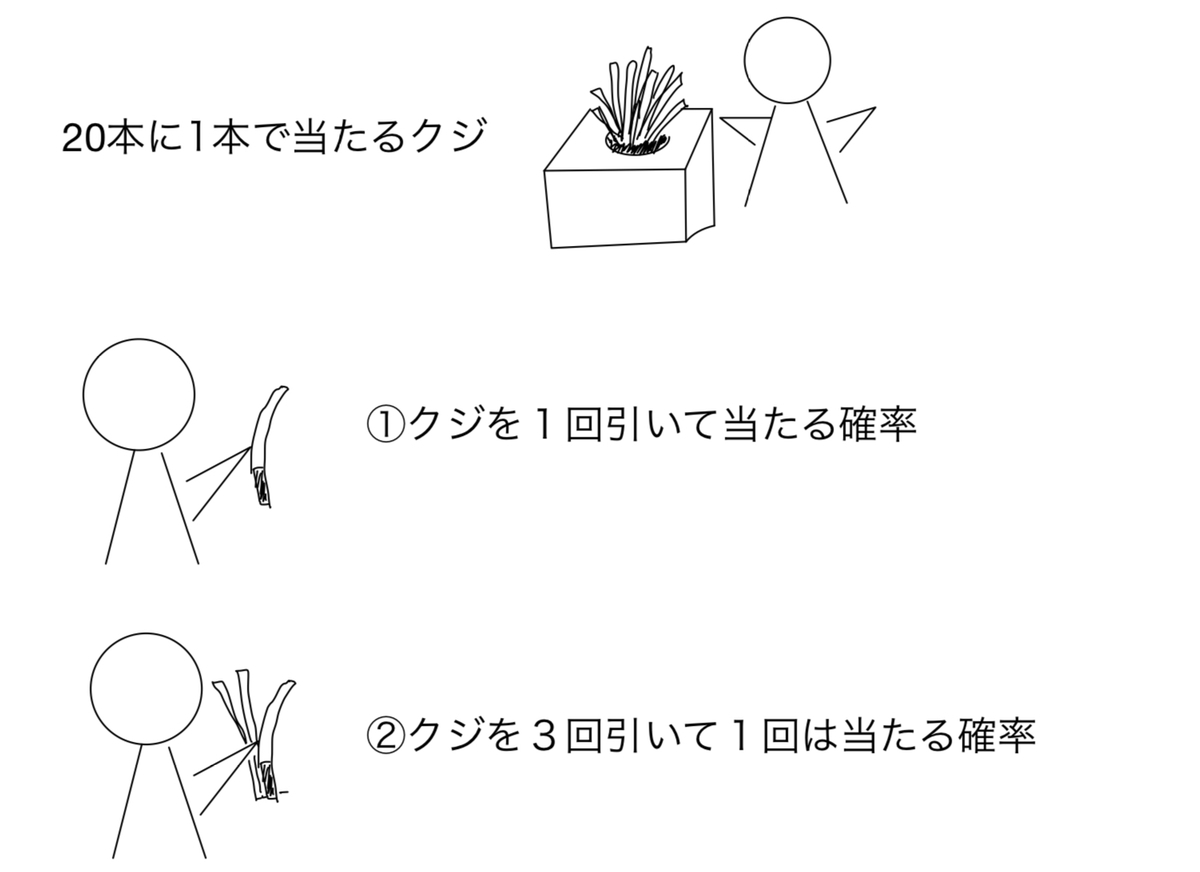
(1)比較群が3つ以上存在する
(2)アウトカムが2つ以上存在する
(3)中間解析など研究終了前にデータの比較が繰り返し行われている
(4)回帰分析などでリスクファクターなどの曝露因子が2つ以上存在する
(5)データが時間によって繰り返し計測され、それぞれの時間において比較が行われている(『今日から使える医療統計』より引用)
今回動画で出てきた例は(1)(2)に当たるものですが、それぞれの場合に応じて補正の方法やP値のとらえ方も異なるので注意が必要です。こちらの本では具体的な解析方法の話も簡単に触れています。
多重検定の問題があるからといって「仮説は常に1個でなければ信用ならない!」という極論に走るわけではなく、適切な補正やとらえ方をすべきである、という点に注意しましょう。
また、当ブログで激推ししているJAMA user’s guideでも多重検定の問題は触れられています。
以下の論文が参考として挙げられており、1980年代には生物統計の分野でBonferroni法や中間解析のO’Brien-Fleming法などが使われていたことが分かります。ガチガチの数式も出てきます。
The analysis of multiple endpoints in clinical trials
仮説検定の根底に関わる問題なので古くから問題点として指摘されているようです。
今回紹介したBonferroni法も、内容は単純そうですが元を正せばボンフェローニの不等式(1936年に報告)という確率論の話から導き出されるものです。
Bonferroni correction – Wikipedia
よくみたらお世話になっている『現代数理統計学の基礎』でも練習問題に出ていましたね。
この辺の話は掘り下げていくと数学と密接に関係した話がそれぞれの内容についてとめどなく繰り広げられるので、興味があるところを少しずつ深めていくのがよさそうです。
さて、次回こそは「標準誤差と標準偏差」についてやっていく予定です。
今回も異動もろもろで仕事が忙しく遅れ気味になりましたが、1か月程度でまた公開できるよう取り組みます。た、多分。











コメントを残す