
さて、この記事ではResults〜Discussionに書かれている内容を中心に、みる点を整理していきたいと思います。
目次:
前回までの記事はこちら
実臨床に役立てるメタアナリシスの読み方① システマティックレビューとメタアナリシスの違い『なぜメタアナリシスのみはダメなのか』
実臨床に役立てるメタアナリシスの読み方② -Background編〜Methods編前半
実臨床に役立てるメタアナリシスの読み方③ -Methods編中盤①
実臨床に役立てるメタアナリシスの読み方④ -Methods編中盤②
実臨床に役立てるメタアナリシスの読み方⑤ -Methods編後半①
メタアナリシスについてより詳しく学ぶ①-fixed effects model, random effects modelと異質性
まとめたページと参考文献はこちら
フォレストプロットの見方と結果の一貫性
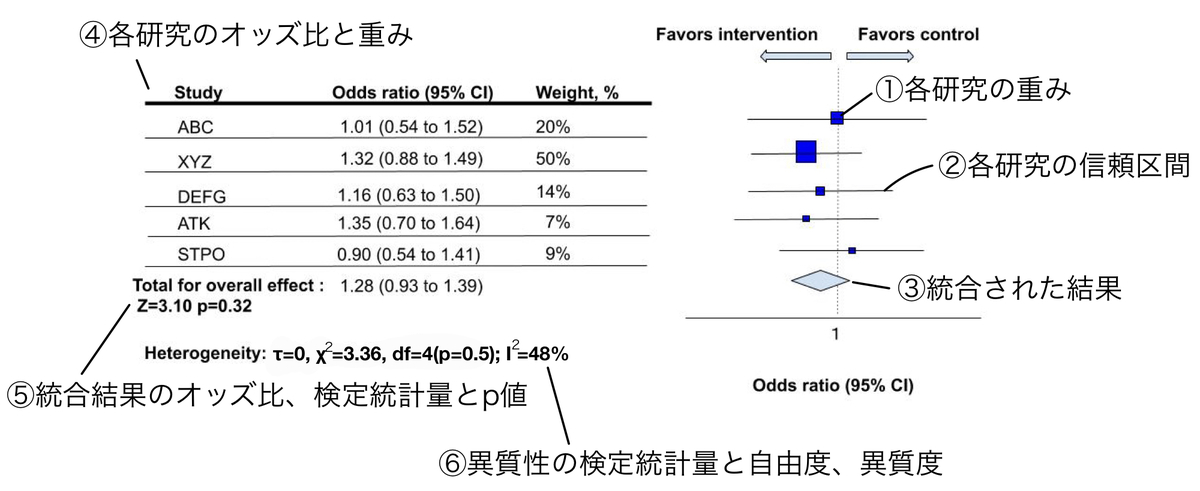
メタアナリシスにおける結果は基本的にフォレストプロットと呼ばれる図表で表現されています。それぞれの項目が指し示している数値や意味について簡単に説明してみましょう(図の数値は適当です)。

①各研究の重み
右側にあるフォレストプロットの四角の大きさが各研究の重み(サンプルサイズと関連)を示します。大きければ信頼区間も小さく規模の大きい研究と言えます。
②各研究の信頼区間
算出された各研究のオッズ比の95%信頼区間を示します。
③統合された結果
全ての研究を統合した結果を示します。菱形の端が95%信頼区間、中心が統合された結果の値を示します。
④各研究のオッズ比と重み
右側のプロットの実際の数値を表したものです。
⑤統合結果のオッズ比と検定統計量、p値
統合された結果のオッズ比が各研究のオッズ比の下に書いてあります。また、「Z=」で示されているのは検定統計量と言われる仮説検定の際に使われる数値です。p値の算出に使われるだけなので、普通に読む際は気にしなくて良いと思われます。
⑥異質性の検定統計量と自由度、異質度
τ(タウ)値は前回記事で書いた変量効果モデル(random effect model)における“研究毎の偏り“を示す分散です。固定効果モデル(fix effect model)を使っている場合は必ずここが0になっています。
変量効果モデル、固定効果モデルについてわからない方はこちら
メタアナリシスについてより詳しく学ぶ①-fixed effects model, random effects modelと異質性-
隣にあるχ(カイ)二乗値は異質性の仮説検定をする際に使われる検定統計量です。これも普通に読む際は気にしなくて良いと思います。
dfはdegree of freedomの略で自由度という数値です。独立に動ける変数の数を示しており、推定する数値の分だけ自由度が下がるので多くの場合は(統合する研究数-1)となっていると思います。今回は5−1=4ですね。これも臨床的に読む分には気にしなくて良いでしょう。隣のp値は異質性があるかどうかを仮説検定した数値で「有意差がつく=異質性がある」という意味になります。
一番右のは前回記事で書いた異質度ですね。
フォレストプロットの基本的な見方は以前の記事にも書いています。ここで書いたように大事なのは結果の一貫性があるかどうかです。
各研究の結果が一貫して良いもの、あるいは悪いものであればそれだけ統合された結果には信頼性が出ます。もちろんそれはここまでの記事で説明していた報告バイアスなどの問題がない前提です。
フォレストプロットを見ると結果の一貫性があるかどうかはパッとみて分かるので非常に便利であると言えます。
また、異質性の評価もこの図からわかります。異質性があまりに大きい場合はみているものがバラバラのものを無理やり集めている可能性が考えられます。そうなると、まるで違うものを統合してただ数値だけ出している、という“リンゴとオレンジの問題”が出てきてしまうため、注意が必要です。
感度分析をしているか
Resultに関して、結果の頑健性がどうかを評価する上でみておきたいのは「感度分析をしているかどうか、またどう行なっているか」という点です。
感度分析とは、データ分析する基準を変えたりしても結果が変わってしまわないかどうか確認することで、結果の頑健性を調べるための分析のことです。
データを分析する際の基準として、必ずしも明確な理由のない恣意的な基準が入ってしまうことがあります。
例えば、高齢者について調べた研究で高齢者の基準を60歳にするのか、65歳にするのか、あるいは70歳にするのかという点は、なんとなくキリが良いからという理由だけであって、明確な医学的理由があるわけではありません。
基準を変えて分析してみても結果が変わらなければ、良いことになりますし、変わってしまうようだと結果の信頼性は揺らぎます。
Cochrane handbookでは「対象となる研究の検索方法」「組み入れ基準」「どのデータを解析するか」「どんな解析方法にするか」といった点で感度分析が使われうることが述べられています。
Chapter 10: Analysing data and undertaking meta-analyses | Cochrane Training
例えば「どんな解析方法にするか」という点では、前回記事で述べていた固定効果・変量効果モデルはどちらが適しているか明確な基準がないため、感度分析としてそれぞれのモデルを行なって結果に違いがないか確認されていることがあります。
感度分析とサブグループ解析の違い
一部のデータに絞って解析をしなおしたりする点でサブグループ解析と似通っているように思われる場合もあるのですが、両者は明確な違いがあります。
感度分析は上述したように結果の頑健性を調べるための方法であるため、結果の推定値にはあまり大きな意味がありません。サブグループ解析はそれぞれのグループの推定値がどうなのかを調べて比較することに意味があるので(偶然かもしれないがもしかしたら大きく数値が異なるものがあるかもしれない)意味合いが異なると言えるでしょう。
臨床での適用はどうか
結果が基本的にオッズ比で出されることになりますが、臨床的には解釈がしにくくなります。そこで、前向き研究には限られますが、統合した数値を絶対リスク減少(ARR; absolute risk reduction)に変換し、さらにNNT(number needed to treat)やNNH(number needed to harm)まで割り出すと臨床的には非常に使いやすいものとなります。
例えば、コクランの脳梗塞急性期に対するアスピリンのメタアナリシスでは、統合された結果のNNT,NNHが表にしてまとめられています。

(Oral antiplatelet therapy for acute ischaemic stroke | Cochraneより引用)
コントロール群の平均的なイベント率も算出した上でこのような表にまとめており、とても分かりやすいです。エビデンスの妥当性という意味とは少し異なりますが、臨床的に解釈ができないようでは意味をなさないので、こうした数値の算出は重要な点であると言えます。
Discussionで述べられること
メタアナリシスのガイドラインであるPRISMA statement2020ではDiscussionにおいて「他のエビデンスと比較した際の結果の一般的な解釈」、またlimitationとして「レビューされている個々の研究の限界」「レビューのプロセスの限界」、さらに今回得られた知見をどうしていくかに関して「臨床への適用、今後の研究との関連」を述べるように指示されています。
「結果の一般的な解釈」は過去の似通った臨床的疑問のある論文と比較して、結果をどう解釈すべきかを示します。
「レビューされている個々の研究の限界」では研究の規模が小さいものやrisk of bias、欠測データの問題について論じます。不確実性が高いデータを集めても結局は大きなRCTでひっくり返される事がある、というのは以前に書いた通りなので、個々の研究の問題はメタアナリシスそのものの問題に直結しています。
「レビューのプロセスの限界」はmethod編で述べた“網羅的な検索“や“報告バイアス”の問題がどこまであるかを論じるものです。こちらも今までに述べていたようにメタアナリシスはあくまで後付け解析であるため、必ずこういったバイアスの影響を受けますから、問題点があればそこについて述べていき必要があります。
まとめ
・フォレストプロットでは各研究の結果の一貫性を通覧し、異質性の確認をする
・感度分析で結果の頑健性を確認する
・discussionでは結果が受けるバイアスが説明されているか注意する
ここまでざっとメタアナリシスの読み方について一度考えてみました。最初で述べたようにメタアナリシスであれば良いエビデンスというわけではなく、質について検討する方法は必ず持っていないといけません。とはいえ、本当に全て吟味するのは時間がかかり過ぎるので、ここまでの記事で紹介した内容でざっと最低限の質に関する部分を確認できると良いかと思っています。まとめページの参考文献にメタアナリシスについて論じているものを色々置いてあるので参照いただければ幸いです。










コメントを残す